NLP guided transformers
Met bewuste, vanuit de taalkunde gekozen bewerkingen op de Nederlandse taal en het tokenizerproces zijn transformers effectiever te trainen voor het Nederlands. We doen hierbij een aantal symbolische bewerkingen die de distributie van de tokens aanzienlijk verbeteren ten voordele van het trainingsproces en eenvoudig in de output kunnen worden omgedraaid zonder de betekenis van taal te veranderen. De bewerkingen richten zich op het concentreren van kennis en het verminderen van ambiguïteit van tokens met computationeel efficiënte NLP technieken.

Ensemble Learning voor chatbots
Een chatbot die bestaat uit 1000 kleine neurale netwerken, klinkt in de tijd van grote modellen misschien vergezocht. Toch bieden ensembles van neurale netwerken enorm veel voordelen. Kleine onderdelen zijn makkelijker en apart te (her)trainen en de totale ensemble kan een groter model in performance benaderen en zelfs overschrijden. En geeft het boek "A Thousand Brains: A New Theory of Intelligence" van Jeff Hawkins (e-book) ons misschien al een indicatie dat het menselijk brein net zo werkt? We trainden al effectief chatbots met duizenden intents, en kunnen we dit nog verder opschalen op standaard hardware? Kunnen we tevens ons eerdere succes op het gebied van microbots hier toepassen?


Semantic Instruct
Hoe kan je de gespreksvrijheid van open dialoog met een Large Language Model (LLM) benutten en kaderen in bruikbare en doelgerichte dialogen voor bedrijven? Recentelijk experimenteerden wij met een veelbelovende methodiek die we zelf "semantic instruct" noemen. In tegenstelling tot traditionele chatbot flows, waarbij elke vraag in een dialoog letterlijk wordt afgevangen en opgevoerd, heeft semantic instruct een monitorend karakter en stuurt bij in vorm van instructies i.p.v. vooropgestelde antwoorden.

Information Pieces
Large Language Models hebben afgelopen jaar op samenvattingsgebied indrukwekkende resultaten laten zien, maar missen nog altijd een belangrijk punt: zekerheid. Een samenvatting waar je niet zeker kan zeggen of de belangrijkste onderwerpen in de samenvatting voorkomen, vermindert het aantal toepasbare use-cases drastisch. Information Pieces is een samenvattingsstrategie die ons helpt meer consistentere en begrijpbaar blijvende samenvattingen te schrijven.
Lees meer: "Wie A zegt moet ook B zeggen"
Robust Language Modelling
Predictieve taalmodellen proberen hun foutmarge te verkleinen met behulp van een enorme hoeveelheid data, waarbij de aanname is dat de massa van data een representatie is van het correcte antwoord. Het nabootsen van data maakt deze modellen zeer gevoelig voor het napraten van een dataset, waarbij het fundament of achterliggende redenatie tussen input en output niet goed wordt aangeleerd. In ons huidig onderzoek en ontwikkeling van Voice Marker II bouwen we geheel nieuwe methodieken voor het robuust opbouwen van feitelijke kennis met een sterker redenatie- en referentiekader.
Tekstverbanden met coreferentie
In onze taaltechnologie speelt coreferentie een essentiële rol. Met onze oplossingen voor coreferentie kunnen we de belangrijkste verbanden in tekst beter herkennen en leggen we een basis die de samenhang van een verhaal beter begrijpt om bijvoorbeeld een betere samenvatting te maken, een chatbot-gesprek beter te begrijpen, een uitgebreide vraag op te lossen en meer kennis te leren uit tekst op een gestructureerde manier.

Streaming NLP
Streaming NLP maakt natuurlijke taalverwerking mogelijk in de meest vroege stadia van de zin, direct vanaf de eerste woorden. Streaming NLP stapt af van de stapsgewijze, gelaagde manier van taalverwerking van traditionele NLP-systemen. Tijdens de seriële verwerking is directe informatie-uitwisseling tussen tokenization, POS- en NER-tagging mogelijk, resulterend in betere verwerking. De technologie reduceert de complexiteit van ons NLP-systeem aanzienlijk en de snellere verwerking biedt potentie voor real-time toepassingen.
Lees meer: "Streaming NLP"
Flexibele chatbots met Microbot architectuur
Geïnspireerd op schaalvoordelen uit de natuur en ICT vormen microbots samen de elementaire bouwstenen voor grotere en geavanceerdere bots. Met microbots verleggen we de grens van bots met gesloten gestuurde dialogen, naar geavanceerdere use-cases met open en wederzijdse communicatiemogelijkheden. De architectuur is uitermate geschikt voor educatieve en informatieve domeinen waarbij het gesprek kan worden gevoerd over de content zonder het gesprekspad te willen vastleggen.
Lees meer: Wat zijn microbots?

Betere beurtwisseling met Response Sensing
Veel chatbots communiceren volgens een om-en-om principe en voelen daarmee onnatuurlijk aan. Een gesprek is spreken en luisteren wanneer dat nodig is. Response Sensing is een technologie waarbij een chatbot automatisch detecteert wanneer het zijn beurt is om te spreken. Je kan zo makkelijker meerdere dingen tegen de chatbot zeggen zonder storende onderbrekingen.
Lees meer: Wat is Response Sensing?
Webpage Awareness: gesprekken over een webpagina
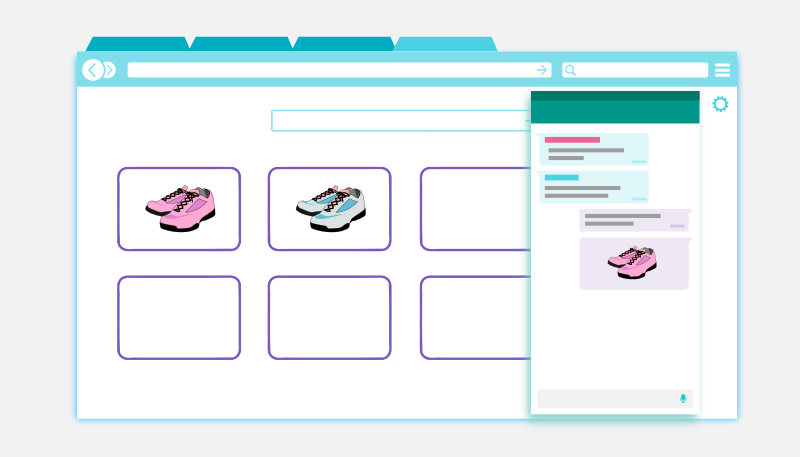
Webpage Awareness is een technologie die het mogelijk maakt op een website een chatbot rekening te laten houden met de pagina-inhoud. Hiermee verleggen we de grens van een chatbot als los communicatiekanaal op een website naar het ontwerp van chatbotdialogen die kunnen gaan over een pagina. Omdat de chatbot "ziet" wat een gebruiker ziet, maak je een gesprek een stuk relevanter. Weet het onderwerp al voor een gesprek begint, geef aanvullende informatie en stel minder onnodige tegenvragen.

Auto-SSML: betere uitspraak van voicebots
Met Auto-SSML past ons platform automatisch regels toe voor optimale uitspraak van voicebots en daarmee de verstaanbaarheid. Hierdoor hoeven we minder tijd te besteden aan het optimaliseren van de stem en klinkt deze zo optimaal mogelijk.