Effectiever trainen van Nederlandstalige taalmodellen
Weet jij uit hoeveel woorden het Nederlands bestaat? Of uit hoeveel verschillende woorden alle talen in de wereld samen bestaan? Talen bestaan gezamenlijk uit vele miljoenen woorden met een onbekende limiet. Large Language Models (LLMs) passen tokenizers toe om tekst op te knippen in tokens (woordstukjes) en het aantal tokens te begrenzen tot een heldere vaste grootte. Deze gelimiteerde en vaste grootte is evident aan de vooraf gedefinieerde grootte van neurale netwerken in de transformer-architectuur en de beschikbare hoeveelheid hardware.
Maar hoe je tekst opknipt, kan op veel verschillende manieren. Bij het opknippen kunnen individuele tokens in betekenis verzwakken en overlap creëren tussen tokens die niet met elkaar te maken hebben. Ongeoptimaliseerde tokenizers vereisen een grotere hoeveelheid data om onderscheid te maken in tokens aan de hand van hun omliggende voorbeelden en verzwakken het trainingsproces. In het Nederlands liggen er diverse kansen om tokenizers te optimaliseren die een effectieve balans creëren tussen hergebruik van tokens en reductie van ambiguïteit, door in het bijzonder slim te kijken naar de rol van zelfstandig naamwoorden en werkwoorden. Hiermee kan je effectiever taalmodellen trainen met de minder beschikbare hoeveelheid data in het Nederlands, tegen lager trainingsbudget.

Van tekst naar tokens
De eerste bewerking die tekst ondergaat in grote taalmodellen (LLMs) is het opknippen daarvan. De zogeheten tokenizer. Een belangrijk doel van de tokenizer is tekst zodanig op te knippen in woordstukjes (tokens) zodat je met slim hergebruik van woordstukjes alle unieke woorden in een taal kan maken, inclusief nieuwe en onbekende woorden. Hiermee wordt het aantal mogelijke woordstukjes begrensd tot een heldere vaste grootte. Deze vaste grootte is essentieel omdat de neurale netwerken waaruit LLMs bestaan, niet in grootte kunnen wijzigen en door de beschikbare hoeveelheid hardware worden begrensd.
Het opknippen van tekst heeft een diepgaand effect hoe LLMs woorden kunnen interpreteren. Hoe groter een tokenizer, hoe meer woorden je volledig intact kan huisvesten zonder dat opknippen noodzakelijk is. Maar grote tokenizers resulteren ook in een grote hoeveelheid benodigde computerkracht.
Heeft een tokenizer een kleinere grootte dan woorden in een taal, dan zullen woorden hoe dan ook moeten worden opgeknipt in stukjes. Hergebruik wordt dan essentieel om binnen de limiet van de tokenizer te blijven. In de praktijk worden er altijd woorden opgeknipt. De Nederlandse taal bestaat uit gemak uit meer dan 0,5 miljoen woorden en zelfs in de grootste modellen van de hyperscalers (zoals Google, OpenAI) hebben tokenizers een beperkte beschikbare ruimte hiervoor, laat staan ruimte voor alle woorden in alle talen. Een woord als ‘autoverzekering’ wordt bijvoorbeeld door GPT-4o opgeknipt als [‘aut’, ‘over’, ‘zek’, ‘ering’]. GPT-4o heeft een totaal tokenbudget van maximaal 200k tokens voor alle talen waarop GPT-4o getraind is. Doordat de meeste grote taalmodellen getraind zijn op het bronnen met Engels als de dominante taal, zijn tokens doorgaans het meest linguistisch efficiënt voor Engels.

Voorbeeld van tekst getokenized op GPT-4o
Opknippen versus ambiguïteit
Knip je woorden op, dan wil je zorgvuldig de schaar zetten op de plekken die linguistisch correct zijn, zodat de transformer-architectuur de unieke betekenis op specifieke tokens makkelijker kan concentreren. Een woord als “bedrijf” zou de tokenizer onverhoeds op kunnen knippen in “be” en “drijf” maar levert overlap en mogelijke verwarring met het voorvoegsel “be-“ (of Engels werkwoord ‘be’) en het werkwoord “drijf”. Sommige woorden wil je eigenlijk überhaupt niet opknippen, omdat opknippen hun betekenis verzwakt en/of onbedoelde ambiguïteit veroorzaakt. Hoe meer dubbelzinnigheid een token heeft, hoe meer omliggende tokens noodzakelijk zijn om het onderscheid te bepalen en dus hoe meer data nodig is. Maar opknippen is onvermijdbaar gezien we het aantal tokens willen reduceren. Dus waar in de Nederlandse taal kan je dit het meest effectief doen?
Efficiënter gebruik van tokens: het “pure” zelfstandig naamwoord.
Kijk je naar het Nederlands dan is de woordsoort die bij verre de meeste unieke combinaties oplevert, het zelfstandig naamwoord. Dit is ook logisch: Ieder object in de wereld om ons heen, van tafel, vlinder tot plant, is benoemd als een zelfst. naamwoord. Het is in principe lastig te bepalen waar de exacte grens in aantal zelfstandige naamwoorden ligt. Analyse van een dataset van 700M+ woorden leverde al zo’n 237.000 unieke zelfstandige naamwoorden op. Maar Nederlandstalige zelfstandig naamwoorden hebben ook de eigenschap dat het vaak samengestelde woorden zijn en aan elkaar geschreven. (In het Engels schrijven we deze meestal los met een spatie). Een woord als “autoverzekering” bestaat uit de zelfstandige naamwoorden “auto” en “verzekering”. Beide woorden zijn niet verder opknipbaar zonder hun betekenis te verliezen. Dit leidt tot de belangrijke onderzoeksvraag: Hoeveel van de echte “pure” zelfst. naamwoorden zijn er? Ofwel, hoeveel niet opknipbare zelfstandige concepten zitten er in de Nederlandse taal, die in alle andere gecombineerde zelfstandig naamwoorden worden gebruikt? En daarin zit het interessante: Slechts 13.000 pure, niet-opknipbare zelfstandig naamwoorden worden in meer dan 90% van alle samengestelde zelfstandig naamwoorden gebruikt. En daarbij de opmerking: deze lijst bestaat nog uit meervoud en enkelvoud en verkleinwoorden (boot, boten, bootje, bootjes) dus het werkelijk aantal is nog kleiner.
Losstaand van het precieze getal, is het duidelijk dat we kunnen stellen dat er een enorme verhouding zit in het aantal woordcombinaties en een veel kleiner aantal daadwerkelijke zelfstandige concepten die je als mens moet leren om deze woorden samen te stellen. Begrijp je het concept van ‘verzekering’ en het concept ‘auto’, dan snap je snel het concept ‘autoverzekering’. Snap je het gecombineerde concept ‘autoverzekering’ dan is de uitleg richting ‘zorgverzekering’ of ‘reisverzekering’ waarschijnlijk ook sneller gemaakt. De reductiefactor is een optimalisatiekans voor tokenizers in de Nederlandse taal, omdat je meer uit de beschikbare data kan halen en de transformer-architectuur zich gunstiger kan concentreren op betekenisvolle tokens. Train je een kleine transformer inachtneming van deze “core nouns”, zien we een positief effect van de leercurve en generatieproces.
Beter leren van hiërarchie, dankzij pure zelfst. naamwoorden.
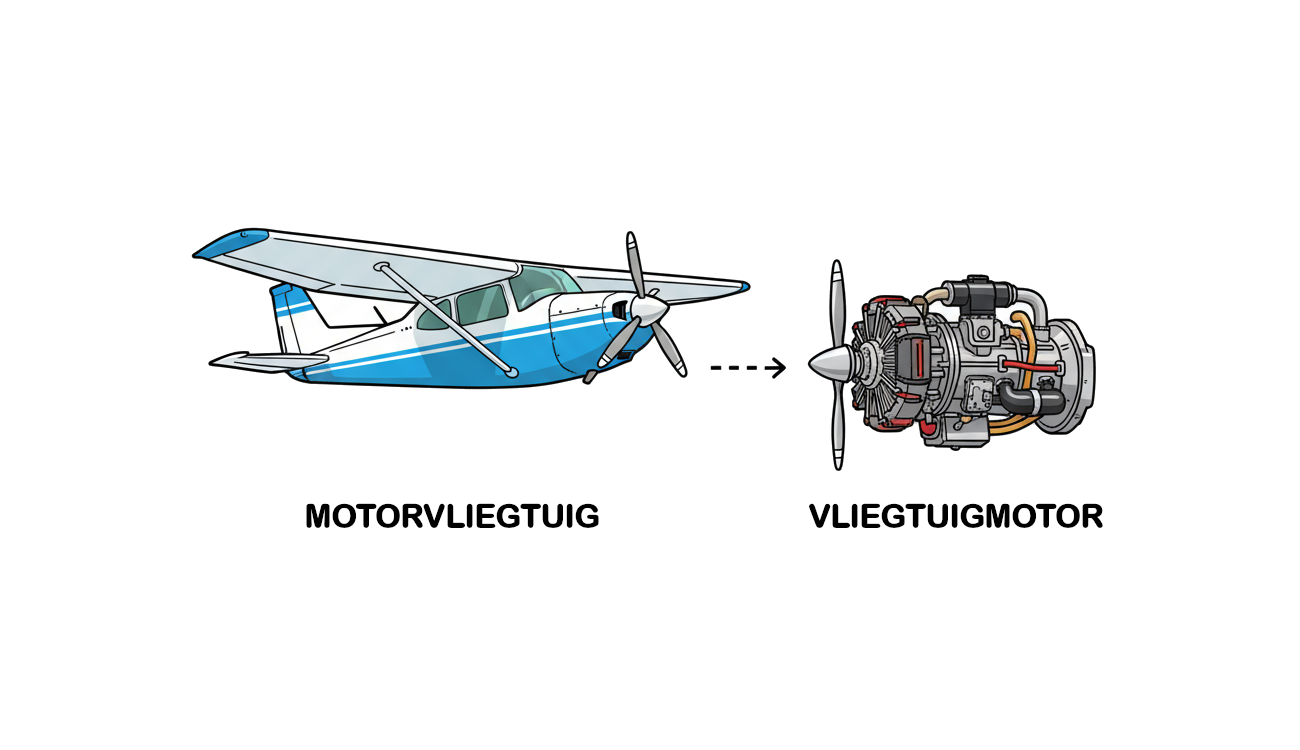
Hoe zelfstandig naamwoorden worden opgebouwd, vormt een belangrijke basis in de hiërarchie van welke objecten onderdeel zijn van andere objecten. Een voorbeeld als “deurknop” betekent een “knop van een deur”. Een woord als “motorvliegtuig” betekent “vliegtuig met een motor” en is een ander object dan “vliegtuigmotor”, motor van een vliegtuig. Het laatste zelfst. naamwoord in een combinatie is het leidende object, de eerste zegt iets over de combinatie. Gunstig opknippen helpt bij het beter benadrukken van deze hiërarchie en het effectiever kunnen leren van een “world model”.
Effectiever maken van de sample frequentie en datadistributie van tokens.
Het spel van het effectiever opknippen van tekst naar tokens heeft een belangrijk ander bedoeld effect: distributie van tokens. Knip je tekst normaal bij iedere spatie in woorden op, zullen bepaalde woorden veel vaker voorkomen dan anderen. Dit is logischerwijs de natuur van taal. Knip je tekst op in tokens, zullen wederom bepaalde tokens (woordstukjes) vaker voorkomen dan andere tokens, maar waar je nu zelf kiest waar je opknipt, bepaal je ook zelf de daadwerkelijke frequentie van ieder token. Waar tech bedrijven vaak stellen “we need more data” om meer voorbeelden van bepaalde woorden te krijgen, kan je in je bestaande data ook meer voorbeelden creëren van tokens door de frequentie effectief te benutten. We vonden meer dan 750 zelfstandig naamwoorden als variaties op bedrijf, en deze leren allemaal iets over dit hoofdconcept. Knip je gunstiger op ten bate van het hoofdconcept, dan is dit gunstig voor het leerproces.
Reductie van ambiguïteit: De NLP enhanced transformer
Onderzoek je de Nederlandse taal, dan zijn er veel woorden die dubbele betekenis kunnen hebben. In het bijzonder zijn er meer dan 1000 werkwoorden die met zelfst. naamwoorden kunnen overlappen (ik werk, het werk, ik vuur, het vuur etc). Ook een woord als ‘zijn’ komt zeer vaak voor in zowel werkwoordelijke als bezittelijke vorm (jullie zijn, zijn tas). Technisch is het eigenlijk vervelend dat eenzelfde symbool (lees: woord) meerdere betekenissen kan hebben afhankelijk van de omliggende situatie. Als we dit principe bij verkeersborden zouden toepassen, en borden een dubbele betekenis krijgen, zou het ook een stuk lastiger worden te kunnen acteren op iedere verkeersregel.
Veel ambigue woordsoorten zijn te onderscheiden met traditionele NLP, en vereisen t.o.v. de transformer relatief weinig compute. Train je een kleine transformer op met een tokenizer waarbij je deze ambiguïteit zoveel mogelijk wegneemt (ofwel overlappende woorden andere symbolen laat zijn), zie je een versneld en wederom verbeterd effect op het generatieproces. Zelfs in de traditionele word-embedding algoritmes als Word2Vec (2013) en fastText (2015) waren deze positieve effecten zichtbaar. Bij word-embeddings helpt het met name vanwege het taalkundig feit dat synoniemen van woorden overeenkomen met de woordsoort. Dit wil zeggen: in een zin kan je een werkwoord vervangen door een ander werkwoord als synoniem maar niet door een zelfst. naamwoord. Als de transformer een werkwoord moet voorspellen, moet je het ook makkelijker maken alle werkwoorden goed te kunnen onderscheiden.
Herschrijven van taal?
Momenteel onderzoeken we de effecten van het verder effectiever coderen van taal ten bate van de tokenizer voor de transformer-architectuur. De focus ligt daarbij op object concentratie (zelfst naamwoorden) waarbij je het aantal schrijfwijzen van hetzelfde object verder reduceert. In onze taal hebben we bijvoorbeeld te maken met verschillende spellingsvormen om enkelvoud en meervoud van zelfst. naamwoorden aan te geven, maar blijft het hetzelfde object. Als je weet wat een ‘bedrijf’ is, dan weet je ook wat ‘bedrijven’ zijn. Anders gezegd, tokens als ‘bedrijf’ en ‘bedrijven’ zijn slechts een duiding in het verschil in aantal. Dit leidt tot de onderzoeksvraag: Zou je tokens verder kunnen concentreren waarbij je een universeel meervoudstoken introduceert? Ofwel, wat als onze officiële spelling ‘bedrijf’ en ‘bedrijf-en’ was geweest (ja de f doet pijn aan je ogen, maar het is technisch effectiever!). Of wat als je tokenized met het proces ‘<bedrijf>’ versus ‘<meervoud><bedrijf>’ of ‘<bedrijf><meervoud>’ (ofwel een prefix of suffix token). Dit lijkt wellicht vreemd maar in sommige talen is dit normaal. Wordt vervolgd!
De tokenizer is de eerste stap die bepaalt hoe Large Language Models tekst verwerken en interpreteren. Deze stap is essentieel om de enorme en onbekende hoeveelheid woorden in taal te converteren naar een vaste grootte zodat deze geschikt is voor de transformer-architectuur en begrensde hardware. Ongeoptimaliseerde tokenizers kunnen Nederlandstalige woorden opknippen op linguïstisch onlogische plekken en nieuwe ambiguïteit van tokens introduceren. Dit vermoeilijkt het leren van taal en vereist daarmee meer data met voorbeelden om tokens te onderscheiden. In ons onderzoek concluderen we dat in de woordsoort met de meeste unieke woorden in de Nederlandse taal, de zelfstandige naamwoorden, uit aanzienlijk veel gecombineerde zelfstandig naamwoorden bestaat, en het daadwerkelijk aantal hoofdconcepten dat we hoeven te leren veel kleiner kan zijn. Door de tokenizer te trainen, inachtneming van deze (niet-opknipbare) hoofdconcepten, reduceren we enerzijds het aantal tokens en creëren we een gezonde distributie die de sample frequentie en het leren van verbanden tussen voorwerpen stimuleert. Door tevens een NLP voor een tokenizer te plaatsen die ambiguïteit tussen specifieke woorden reduceert, in het bijzonder tussen veelvoorkomende overlap tussen werkwoorden en zelfstandig naamwoorden in de Nederlandse taal, zien we een positief effect op de leercurve en generatieproces. •
Wil je meer weten welke innovaties Cornelistools B.V. ontwikkelt op het gebied van o.a. taal, AI en LLMs? Neem contact op en/of volg ons!
Geplaatst 10-2025 in LLMs